Litigation Workflow Map: Intake to Verdict Without Rework
.png)

Rework is the silent profit killer in litigation. It shows up as re-reading the same records before every milestone, re-building timelines for each motion, and re-copying facts from medicals into a demand, then into depo prep, then again into trial themes. A clear litigation workflow map solves that by defining what “done” means at each stage, what gets produced, and what must be reusable downstream.
Below is a practical intake-to-verdict workflow you can adopt as a checklist, then operationalize with templates and automation.
The core principle: one source of truth, many downstream work products
Every case has different facts, but the workflow should be repeatable. The goal is to create a single, continuously updated case file that feeds every output:
- Chronology and issue tags that stay consistent from demand through trial
- A damages model that is updated, not recreated
- A witness and exhibit plan that evolves, not restarts
When teams skip this, they pay for it later in late-stage “scrambles” (new associate on the case, a mediation date pulled up, a trial order entered) that force the firm to redo foundational work.
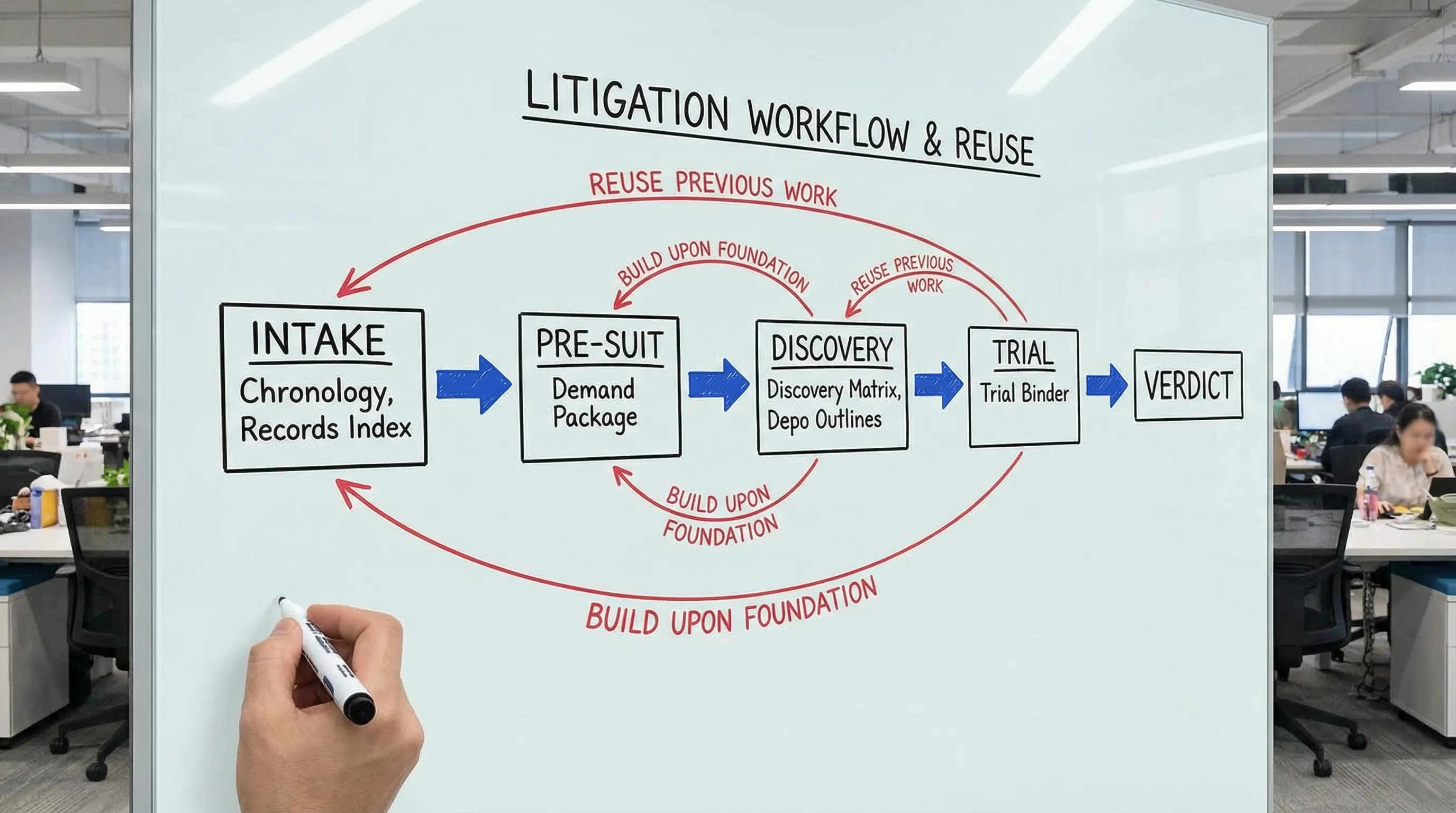
Litigation workflow map (with deliverables that prevent rework)
The map below is intentionally output-driven. If you define deliverables early, you avoid the most common loop: “We’ll organize this later.”
| Stage | Primary inputs | Definition of done (rework-proof deliverable) | Downstream reuse |
|---|---|---|---|
| Intake and conflict | Intake notes, basic docs, parties | Clean party list, conflicts cleared, initial theory memo (1 page) | Case setup, demand framing |
| Triage and plan | Accident report, incident summary, key dates | Litigation plan: venue, limitations, early targets, needed records | Discovery plan, case calendar |
| Record collection | Authorizations, provider list, employment, insurance | Master records index (what requested, received, missing, follow-ups) | Med summary, damages proof |
| Fact development | Records, photos, witness statements | Case chronology + issue tags (liability, causation, damages) | Demand, depo outlines, motions |
| Liability and damages analysis | Chronology, med bills, wage loss | Updated damages spreadsheet + causation notes + defenses list | Settlement, experts, trial themes |
| Demand and negotiation | Analytics + exhibits | Demand package with exhibit map (every claim supported by a cite) | Mediation brief, complaint |
| Pleadings and early motions | Demand file + jurisdiction research | Complaint/answer aligned to the issue tags and evidence | Discovery scope, MSJ record |
| Discovery | RFPs/ROGs, productions, subpoenas | Discovery matrix (requests, responses, deficiencies, meet-and-confer log) | Depositions, motions to compel |
| Depositions | Discovery matrix, chronology, exhibits | Witness-specific depo outline tied to exhibits and admissions goals | MSJ, trial examination |
| Dispositive motions and pretrial | Depo transcripts, expert reports | Motion record with pinpoint citations and exhibit list | Trial prep, settlement leverage |
| Trial prep and verdict | Trial order, exhibit list, jury instructions | Trial binder structure (themes, witnesses, exhibits, objections) | Post-trial motions, appeal |
Where rework actually happens (and how to stop it)
Most “redo” work clusters in three transitions.
1) From records to narrative
Teams often collect documents without turning them into structured, citable facts. The fix is to build a chronology that is:
- Cited (each key fact points to a bates range or document page)
- Tagged (liability, causation, damages, impeachment)
- Updateable (new records slot into the timeline without breaking it)
This is also where AI can help if used correctly: extracting dates, providers, diagnoses, and events into a consistent format, then letting a human validate the story you will actually argue.
2) From discovery to depositions
If discovery responses are stored as PDFs in a folder, deposition prep becomes a second discovery review. Instead, treat discovery like a database:
- Track what was asked, what came back, and what is missing
- Link each deficiency to the element it affects (notice, duty, breach, damages)
- Convert “missing” into a task list with deadlines and escalation steps
That turns depo prep into strategy (admissions and locks), not scavenger hunting.
3) From settlement posture to trial posture
The demand package should not be “the settlement version of the case.” It should be the first full assembly of the trial record, just presented earlier. If your demand is built from a cited chronology and an exhibit map, then:
- Mediation briefs pull cleanly from the same spine
- Your complaint tracks the same theory and proof
- Trial themes align with what you have actually documented
A lightweight workflow you can implement this week
You do not need a massive re-org to get compounding benefits. Start with three artifacts that travel through the case.
The “case spine” folder
Create a single place (physical or digital) that always contains:
- Chronology (cited and tagged)
- Records index (requested/received/missing)
- Damages model (with sources)
- Witness list (what they prove, what you need from them)
A single exhibit map
Even at intake, begin an exhibit map with placeholders (police report, photos, ER records, billing, employment). Updating a map beats rebuilding a binder.
A repeatable intake packet
Borrow a lesson from any service business that needs consistent client onboarding: standard questions, standardized consent, and a predictable flow reduce back-and-forth. If you want an example of how “intake clarity” is presented to consumers, look at how appointment-based practices structure booking and pre-visit information, like Lumina Skin Sanctuary’s consultation and service flow. The point is not the industry, it is the repeatability.
How TrialBase AI fits into an intake-to-verdict workflow
If your biggest bottleneck is transforming raw documents into usable litigation work product, automation is most valuable at the moments you must produce something concrete.
TrialBase AI is positioned for those conversion points: you upload documents and generate litigation-ready outputs like demand letters, medical summaries, deposition outlines, and trial materials in minutes, supported by AI-driven document analysis and a unified workflow for team collaboration.
The practical way to use it without creating new rework is to anchor every generated output to your “case spine” artifacts (chronology, exhibit map, damages model), then update the spine as the case evolves.
If you want to pressure-test your current process, take one active case and ask: “Could I generate a credible demand, a depo outline, and a trial exhibit list from what we have right now without starting over?” If the answer is no, the workflow map above tells you exactly what deliverable is missing.
To see how document-to-work-product automation can slot into that map, visit TrialBase AI.



